
Le web scraping permet de collecter automatiquement des données du web dans une optique de veille concurrentielle, de génération de prospects, d’élaboration de stratégies marketing et commerciales et plus encore. Encore faut-il savoir quels outils utiliser et quels contours légaux régissent cette pratique. Nous vous expliquons tout.

Le web est une source inestimable de données. Et si vous pouviez gratuitement exploiter cette mine d’information ? C’est ce que propose le « web scraping », une technique efficace de collecte rapide et automatisée des données du web. Plus besoin de faire des copier-coller à la main. De nombreux outils réalisent automatiquement cette tâche et traitent des milliers de données en quelques secondes. Chaque solution a ses forces et ses faiblesses. Certaines nécessitent de savoir coder, d’autres non.
À quoi ça sert ? Pour qui ?
Les secteurs qui utilisent le plus le web scraping sont ceux qui manipulent beaucoup de données : e-commerce, finance, médias sociaux, immobilier, presse, sciences… Dans ces secteurs, les métiers qui y ont le plus recours sont le marketing, la finance, les RH, les spécialistes SEO et les data scientists.
Une fois les données collectées, les entreprises peuvent s’en servir pour alimenter leur veille concurrentielle ou enrichir à peu de frais leur propre base de données. Voici ses principaux usages :
- Surveiller des prix et les disponibilités de produits et de services afin de faire de la veille concurrentielle ou analyser les tendances de marché.
- Générer des leads en récupérant automatiquement les noms, prénoms, fonctions et coordonnées de professionnels depuis LinkedIn, Twitter, Google Maps, Indeed…
- Optimiser le référencement d’un site : surveiller son classement dans les résultats de recherche et son positionnement vis-à-vis de ses concurrents.
- Analyser les sentiments en ligne en parcourant les avis clients et les commentaires sur les réseaux sociaux.
- Vérifier automatiquement des liens. C’est notamment utile dans une stratégie d’affiliation pour s’assurer que les liens ne sont pas brisés ou obsolètes.
- Surveiller des offres d’emploi ou collecter des informations sur des candidats potentiels à partir des sites d’emploi ou des réseaux sociaux
- Construire des jeux de données pour entraîner une IA
- Rechercher des violations du droit d’auteur (plagiat d’images ou de textes)
- Collecter des informations sur un sujet spécifique. Par exemple, réaliser une revue de presse automatique des articles et des innovations en matière de production de batteries.
Comment ça marche ?
Le web scraping utilise un scraper, un outil logiciel qui extrait les informations des sites web. Le scraper interagit avec les sites comme le ferait un navigateur manipulé par un humain. Mais au lieu d’afficher les informations, il les recueille et les enregistre pour une analyse ultérieure. Ce processus se compose de quatre étapes :
- requête HTTP : le scraper envoie une requête à l’URL cible pour obtenir le contenu d’une page.
- analyse du code HTML : le scraper identifie les éléments qui concernent les données recherchées.
- extraction des données : les données sont extraites grâce à des sélecteurs comme XPath, CSS ou des expressions régulières (regex).
- stockage des données : les informations sont enregistrées dans des formats exploitables pour leur analyse (Excel, CSV, JSON…).
Comment faire du web scraping ?
Pour les développeurs
Les développeurs sont les maîtres du scraping. Grâce à des langages de programmation associés à des frameworks et bibliothèques spécialisées dans l’extraction de données, ils peuvent créer des scrapers parfaitement adaptés au site web visé et aux données à extraire. Efficacité, évolutivité et maintenabilité sont leurs maîtres mots.
Quel langage privilégier ? Si JavaScript (Node.js), Ruby, C, C++, R ou PHP permettent de faire du web scraping, Python s’est largement imposé ses dernières années grâce à deux outils, BeautifulSoup (une bibliothèque) et Scrapy (un framework).
Faciles à apprendre, rapides et portables (Linux, Windows, macOS et BSD), Python et ses deux compléments permettront de réaliser n’importe quel projet de web scraping.
Voici un exemple de programme Python qui utilise la bibliothèque BeautifulSoup pour récupérer tous les prix des rasoirs électriques sur les pages d’Amazon.fr.
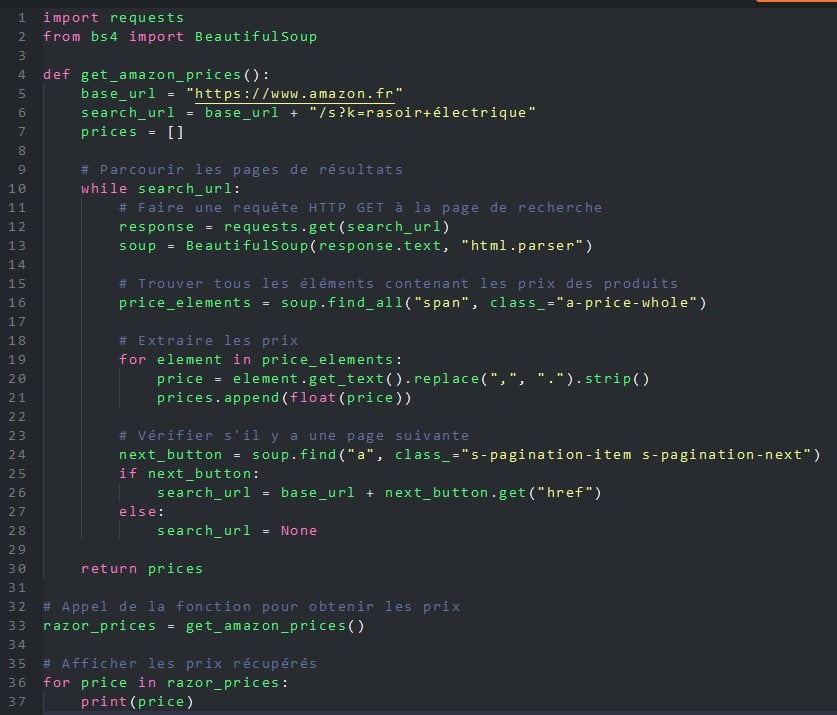
Pour les non-développeurs
Si les développeurs ont toujours l’avantage de créer des outils de web scraping les plus performants et les plus adaptés aux besoins de leurs utilisateurs, ils n’en ont plus le monopole. Ainsi, les non-informaticiens, qu’ils travaillent dans le marketing, la finance ou les RH font de plus en plus appel au web scraping, mais sans coder. Ils utilisent pour cela des outils no-code apparus ces dernières années. En voici quelques-uns.
Les extensions de navigateur
C’est la méthode la plus simple pour aborder le web scraping sans coder : installer une extension dans son navigateur web. Gratuits et simples à utiliser, ces plug-ins fonctionnent tous de la même manière : une fois sur le site cible, vous sélectionnez les éléments que vous souhaitez récupérer (texte, images, URL…), la périodicité (une fois par heure, par jour ou par semaine, par ex. ) et l’extension s’occupe du reste. Parmi les plus connus, citons Web Scraper, Simplescraper, Scraper, Agenty ou Instant Data Scraper.

Les plateformes de web scraping
Autre solution qui ne nécessite pas de connaissances en programmation : passer par une des nombreuses plateformes qui proposent des services de web scraping comme Octoparse, Bright Data, Parsehub ou PhantomBuster. Ces outils permettent – sur abonnement – de collecter les données du web, mais aussi de plateformes sociales comme Facebook, Instagram, Twitter, YouTube… Vous pourrez récupérer des informations sur les hashtags, les mentions, les commentaires et les likes. Ces données pourront être utilisées pour analyser les tendances et les performances des campagnes de marketing.

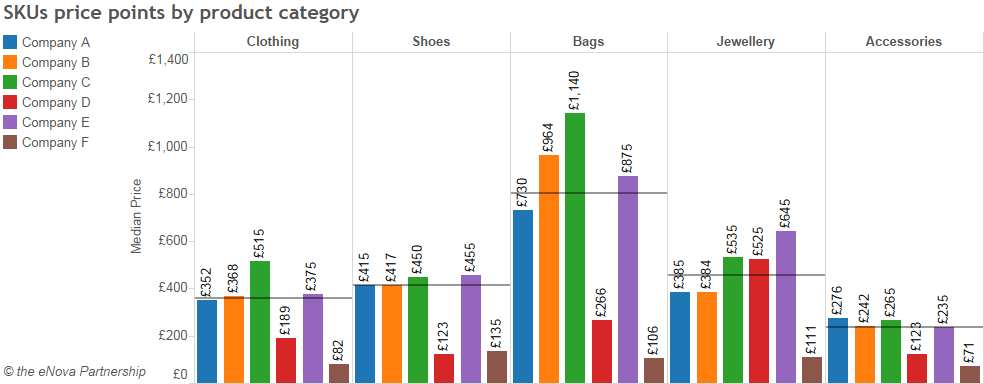
L’utilisation d’une plateforme de web scraping, ici ParseHub, permet de sélectionner les données à traiter (ici, les catégories de vêtements d’un site d’e-commerce), les extraire et les interpréter. Le tableau ci-dessous analyse les prix moyens par catégorie de produits et par fabricant.
Le gros avantage de ces plateformes est de proposer des solutions no-code, fonctionnant sur le cloud en 24/7. Vous pouvez donc planifier les scrapers pour obtenir les données en flux continu ou à intervalles flexibles. Autre avantage : vous avez le choix entre des dizaines de modèles de scrapers prêts à l’emploi, capable de cibler en quelques clics les sites et plateformes les plus populaires. Enfin, ces plateformes cloud déjouent bon nombre des protections mises en place par les sites web pour se protéger du web scraping : rotation d’IP, captchas, proxies, défilement infini…
Les applications d’analyse de données
Google Sheets, Power BI, Excel… les tableurs et les applications de data visualisation permettent d’extraire des données du web plus ou moins facilement.
Parfois, il faudra utiliser des fonctions spécifiques. C’est le cas de Google Sheets qui dispose de fonctions spécialisées : IMPORTXML et IMPORTHTML. Encore faut-il comprendre la structure d’une page HTML pour correctement formaliser la formule et arriver à ses fins.
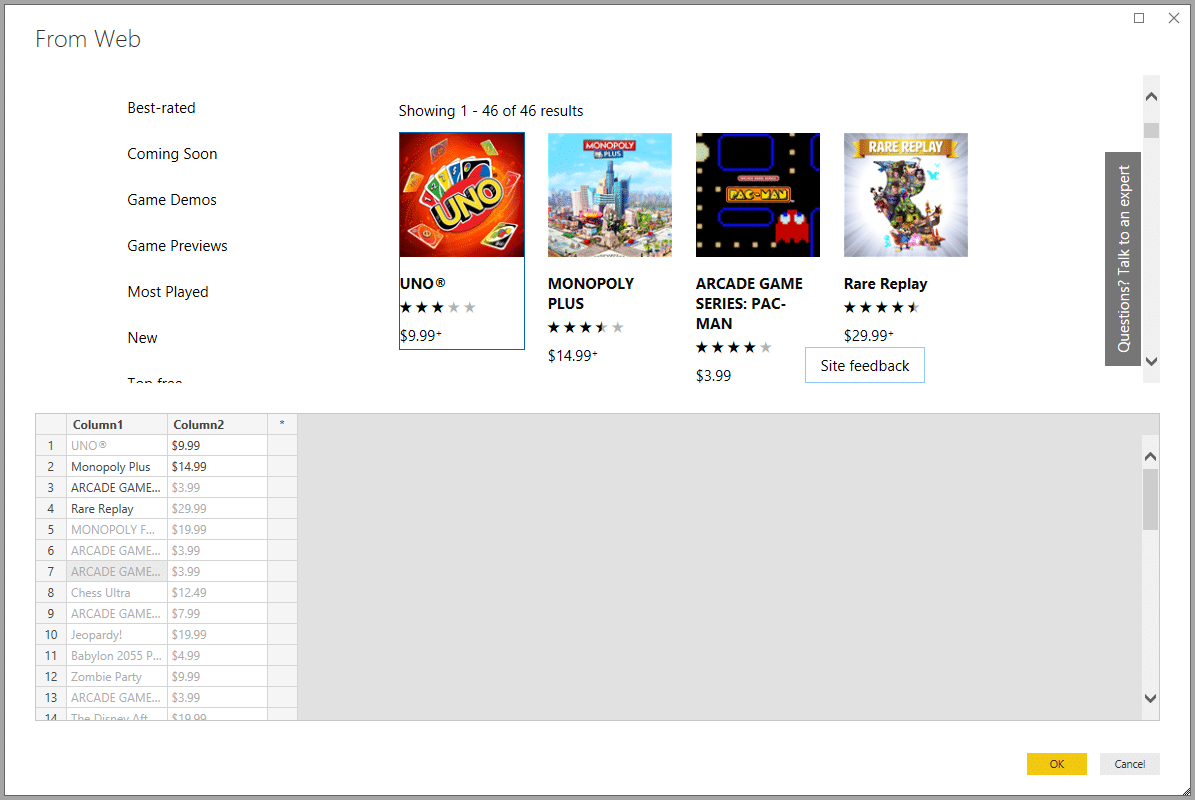
Excel, Microsoft 365 et Power BI disposent de modules spécialisés dans l’extraction de données plus faciles à mettre en œuvre. Ainsi, Excel utilise le module Power Query (depuis Excel 2010) ou un module de requêtes sur le web depuis le menu Données. De son côté, Microsoft 365 bénéficie de la puissance de son module d’automatisation Power Automate. Toujours chez le même éditeur, la solution d’analyse de données Power BI inclut le web scraping dans son menu Obtenir des données. Tous ces assistants proposent automatiquement de récupérer les tables présentes sur les pages web ciblées, mais il est possible de définir d’autres sources de données.
La montée de l’IA
La démocratisation de l’intelligence artificielle, notamment les IA génératives comme ChatGPT, Bing Conversation ou Bard, change la donne. Grâce à ce type d’IA, il est facile de récupérer des informations du web ou de fichiers PDF de manière extrêmement rapide. Ces IA ont toutefois l’inconvénient d’être généralistes et de ne pas pouvoir exporter facilement les données dans des formats structurés.
Pour cela, il faut recourir à des IA spécialisées dans le web scraping comme Scrapestorm, kadoa.com, Nimbleway API ou Browse.ai. Des solutions à partir d’une vingtaine d’euros par mois.
Avec de telles IA, nul besoin de programmer. Il suffit de définir les données à extraire (des prix, par ex.), une ou des sources de données (un ou des sites web) et préciser la fréquence de récupération des données (toutes les semaines, par ex.).
L’IA s’occupe de tout le reste : créer un programme paramétré selon vos choix, extraire les données et vous les transmettre dans le format que vous avez défini (Excel, CSV, JSON…).
Outre leur facilité d’utilisation, leur efficacité et leur rapidité, ces IA de web scraping sont capables de reconnaître et de récupérer n’importe quel type de données (texte, images, vidéos, liens, autres fichiers). De plus, elles ne sont pas bloquées par des pages dynamiques ou les outils habituels de sécurisation mis en place par les sites ciblés, comme les captchas ou le blocage des adresses IP.
Quelles sont les limites du web scraping ?
Le web scraping contribue largement à la prolifération des bots, ces robots logiciels qui parcourent le web en quête de données. Cela devient même une espèce envahissante. Ainsi, une étude de la société américaine de cybersécurité Imperva révèle que les bots ont représenté 47 % du trafic Internet en 2022 !
Les limites techniques
Parmi tous ces bots, on compte des programmes malveillants mais aussi les bots de web scraping qui surexploitent les serveurs qu’ils ciblent. Ils multiplient les requêtes, réduisant ainsi leurs performances, allant parfois jusqu’à les faire planter. Un cauchemar pour tout administrateur système !
Autre conséquence fâcheuse, cette fois pour le marketing : ce trafic non humain fausse les mesures d’audience des sites web ciblés et donc compromet la stratégie de marketing digital de l’entreprise.
Cependant, la défense s’organise. Pour se protéger de cette invasion, de plus en plus de sites recourent à différentes solutions techniques pour bannir les bots : énigmes captcha pour demander aux utilisateurs de prouver qu’ils sont humains, bannissement d’adresses IP, limitation automatique du nombre de requêtes provenant d’une même IP, etc.
Une autre solution consiste à compliquer et changer régulièrement la structure des pages qui s’affichent :
- changer l’architecture des URL (modifier l’ordre des paramètres),
- modifier le code HTML (modifier les noms de classes et d’ID, changer l’ordre des éléments du DOM)
- rotation des templates (si votre site dispose d’un CMS, vous pouvez créer plusieurs modèles de page et les faire tourner)
- offusquer le code (minification, obscurcissement des noms de variables et de fonctions, charger le contenu avec du JavaScript, encoder les données)
- alterner la structure des données (CSV, JSON…)
- changer la structure de l’API si votre site en propose
Grâce à tous ces changements, le code ou les paramètres de la solution de scraping devront être actualisés pour s’adapter, ce qui réduit leur efficacité aussi bien que leur intérêt.
Les limites légales
Comme toute technique de recueil des données, le scraping est soumis aux réglementations française et européenne, mais également aux conditions générales d’utilisation (CGU) propres à chaque site web.
L’usage du web scraping est donc soumis à trois conditions :
1. Respecter les CGU du site source des données
Dans ses CGU, LinkedIn interdit formellement le web scraping :
« Vous vous engagez à ne pas développer, prendre en charge ou utiliser des logiciels, des dispositifs, des scripts, des robots ou tout autre moyen ou processus (notamment des robots d’indexation, des modules d’extension de navigateur et compléments, ou toute autre technologie) visant à effectuer du web scraping des Services ou à copier par ailleurs des profils et d’autres données des Services »
Enfreindre ces CGU expose le contrevenant à des sanctions. Passer outre est périlleux, d’autant que de plus en plus grandes plateformes mettent en place des outils de détection du web scraping.
2. Respecter le RGPD
En plus du respect des CGU, le web scraper doit respecter le RGPD, applicable à tout traitement des données. En cas de non-respect, le montant des sanctions peut s’élever jusqu’à 20 millions d’euros ou dans le cas d’une entreprise jusqu’à 4% du chiffre d’affaires annuel mondial.
3. Respecter les droits d’auteur
Les bases de données sont protégées par le droit d’auteur, et par un droit sui generis (à part entière) protégeant son producteur (articles L. 112-3 et L. 341-1 du code de la propriété intellectuelle). Les peines maximales encourues en cas de violation sont de 300 000 euros d’amende et de 3 ans d’emprisonnement.
La justice a ainsi donné raison le 2 février 2021 au site Leboncoin.fr dont les annonces immobilières ont fait l’objet d’extractions de données par un site concurrent.
En plus du cadre légal, il convient de respecter certaines bonnes pratiques :
- Pratiquer le web scraping en dehors des heures de pointe du site, quand les serveurs sont plus disponibles;
- Limiter les données récupérées à celles dont vous avez vraiment besoin ;
- Utiliser les API et autres moyens (jeux de données…) proposés par le site visé pour éviter de recourir au web scraping.
Le web scraping nécessite d’actualiser régulièrement ses compétences
Malgré ses défis techniques et juridiques, le web scraping reste populaire. Il constitue un formidable outil pour collecter automatiquement des données. ORSYS propose de nombreuses formations en présentiel ou à distance pour utiliser l’une des solutions que nous vous avons présentées.
Les développeurs et les spécialistes des données (data analyst, data engineer…) pourront se former au big data, à l’usage des bibliothèques Python spécialisées en web scraping (scrapy, BeautifulSoup, Selenium…).
Nous proposons aussi des formations pour apprendre à nettoyer et à manipuler les données collectées.
Les développeurs web, RSSI et administrateurs système pourront être intéressés par nos formations sur la sécurité des sites web afin d’empêcher le web scraping et le vol de données.
Les DSI, DPO et juristes pourront suivre nos formations pour maîtriser les enjeux juridiques du RGPD.
Enfin, les non-informaticiens qui souhaitent profiter du web scraping dans leur usage métier pourront se tourner vers nos formations Excel, Google Sheets ou Power BI.
Chacun y trouvera son compte.


