
Le web scraping allows you to automatically collect data from the web for the purposes of competitive intelligence, lead generation, developing marketing and sales strategies and much more. But you need to know which tools to use and the legal framework governing this practice. We explain everything.

The web is an invaluable source of data. What if you could tap into this wealth of information for free? That's what web scraping is all about, an efficient technique for collecting web data quickly and automatically. No need to copy and paste by hand. Many tools automatically perform this task and process thousands of pieces of data in a matter of seconds. Each solution has its strengths and weaknesses. Some require coding skills, others do not.
What is it for? Who is it for?
The sectors that make the most use of web scraping are those that handle a lot of data: e-commerce, finance, social media, real estate, press, science, etc. Within these sectors, the professions that make the most use of it are marketing, finance, HR, SEO specialists and data scientists.
Once the data has been collected, companies can use it to feed their competitive intelligence or enrich their own database at little cost. Here are the main uses:
- Monitor prices and availability of products and services to monitor the competition or analyse market trends.
- Generate leads by automatically retrieving the surnames, first names, functions and contact details of professionals from LinkedIn, Twitter, Google Maps, Indeed, etc.
- Optimising site referencing : monitor its ranking in search results and its positioning in relation to its competitors.
- Analyze online sentiment by reading customer reviews and comments on social networks.
- Automatically check links. This is particularly useful in an affiliation strategy to ensure that links are not broken or obsolete.
- Monitor job offers or collect information about potential candidates from job boards or social networks
- Building data sets to train an AI
- Search for copyright infringements (plagiarism of images or texts)
- Gather information on a specific subject. For example, produce an automatic press review of articles and innovations in battery production.
How does it work?
Web scraping uses a scraper, a software tool that extracts information from websites. The scraper interacts with the sites in the same way as a browser manipulated by a human. But instead of displaying the information, it collects it and saves it for later analysis. This process consists of four stages:
- HTTP request The scraper sends a request to the target URL to obtain the content of a page.
- HTML code analysis The scraper identifies the elements relating to the data you are looking for.
- data extraction Data is extracted using selectors such as XPath, CSS or regular expressions (regex).
- data storage : the information is recorded in formats that can be used for analysis (Excel, CSV, JSON, etc.).
How to do web scraping?
For developers
Developers are the masters of scraping. Thanks to programming languages combined with frameworks and libraries specialising in data extraction, they can create scrapers that are perfectly adapted to the target website and the data to be extracted. Efficiency, scalability and maintainability are their watchwords.
What language should be used? If JavaScript (Node.js), Ruby, C, C++, R or PHP allow web scraping, Python has made a name for itself in recent years thanks to two tools, BeautifulSoup (a library) and Scrapy (a framework).
Easy to learn, fast and portable (Linux, Windows, macOS and BSD), Python and its two add-ons can be used for any web scraping project.
Here's an example of a Python program that uses the BeautifulSoup library to retrieve all the prices of electric shavers on the Amazon.co.uk website.
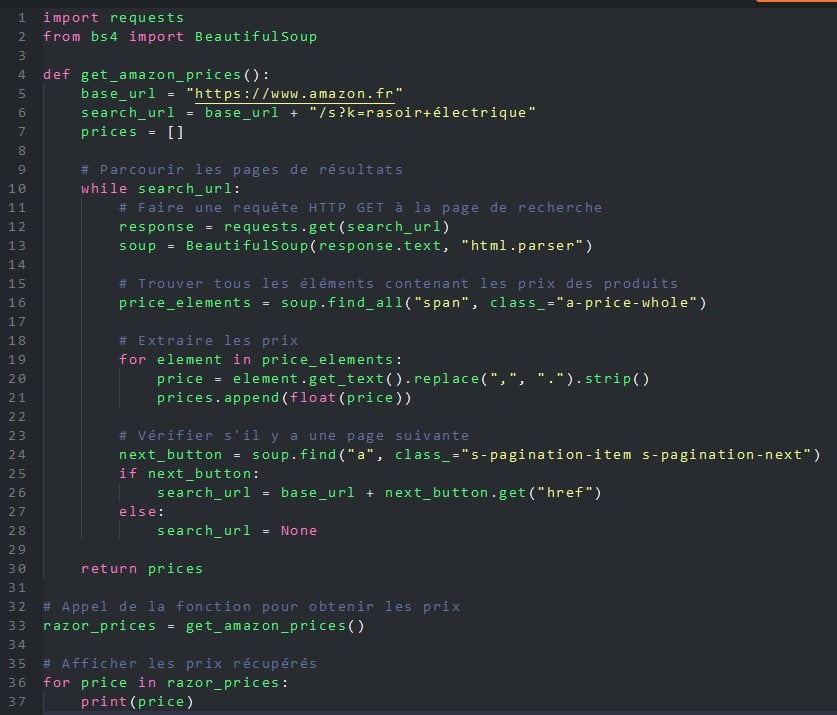
For non-developers
While developers still have the advantage of creating the most effective web scraping tools that are best suited to the needs of their users, they no longer have a monopoly. As a result, non-IT professionals, whether in marketing, finance or HR, are increasingly using web scraping, but without coding. To do this, they use no-code tools that have emerged in recent years. Here are a few of them.
Browser extensions
This is the easiest way to get started with web scraping without coding: install an extension in your web browser. Free and easy to use, these plug-ins all work in the same way: once on the target site, you select the elements you want to retrieve (text, images, URL, etc.), the frequency (once an hour, once a day or once a week, for example) and the extension takes care of the rest. Some of the best-known are Web Scraper, Simplescraper, Scraper, Agenty or Instant Data Scraper.

Web scraping platforms
Another solution that doesn't require programming skills is to use one of the many platforms offering web scraping services, such as Octoparse, Bright Data, Parsehub or PhantomBuster. These tools allow you - by subscription - to collect data from the web, as well as from social platforms such as Facebook, Instagram, Twitter, YouTube, etc. You can retrieve information on hashtags, mentions, comments and likes. This data can be used to analyse trends and the performance of marketing campaigns.

Using a web scraping platform, in this case ParseHub, we can select the data to be processed (in this case, the clothing categories of an e-commerce site), extract it and interpret it. The table below analyses average prices by product category and manufacturer.
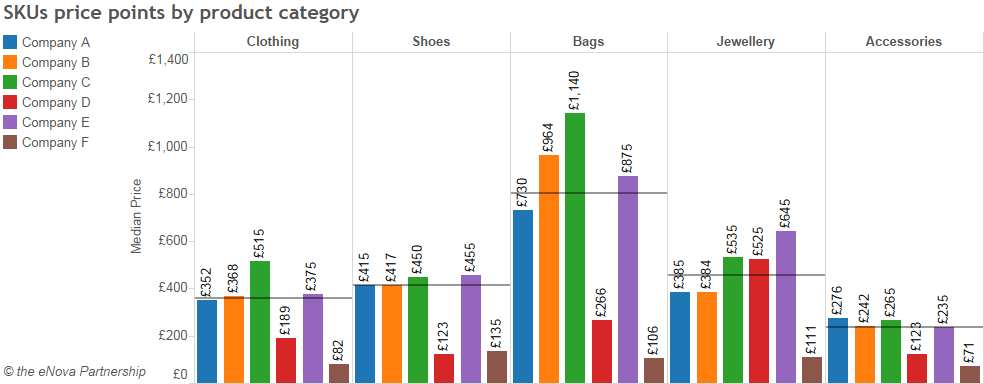
The big advantage of these platforms is to offer no-code solutions, operating on the cloud 24/7. You can therefore schedule scrapers to obtain data in a continuous stream or at flexible intervals. Another advantage is that you can choose from dozens of ready-to-use scrapers., capable of targeting the most popular sites and platforms in just a few clicks. Finally, these cloud platforms bypass many of the protections put in place by websites to guard against web scraping IP rotation, captchas, proxies, infinite scrolling, etc.
Applications data analysis
Google Sheets, Power BI, Excel... spreadsheets and data visualisation applications can be used to extract data from the web with varying degrees of ease.
Sometimes you need to use specific functions. This is the case with Google Sheets, which has specialised functions: IMPORTXML and IMPORTHTML. You still need to understand the structure of an HTML page to correctly formalise the formula and achieve your goals.
Excel, Microsoft 365 and Power BI have specialist data extraction modules that are easier to implement. For example, Excel uses the Power Query module (since Excel 2010) or a web query module from the Data menu. For its part, Microsoft 365 benefits from the power of its Power Automate automation module. Still from the same publisher, the Power BI data analysis solution includes web scraping in its Get Data menu. All these wizards automatically propose to retrieve the tables present on the targeted web pages, but it is possible to define other data sources.
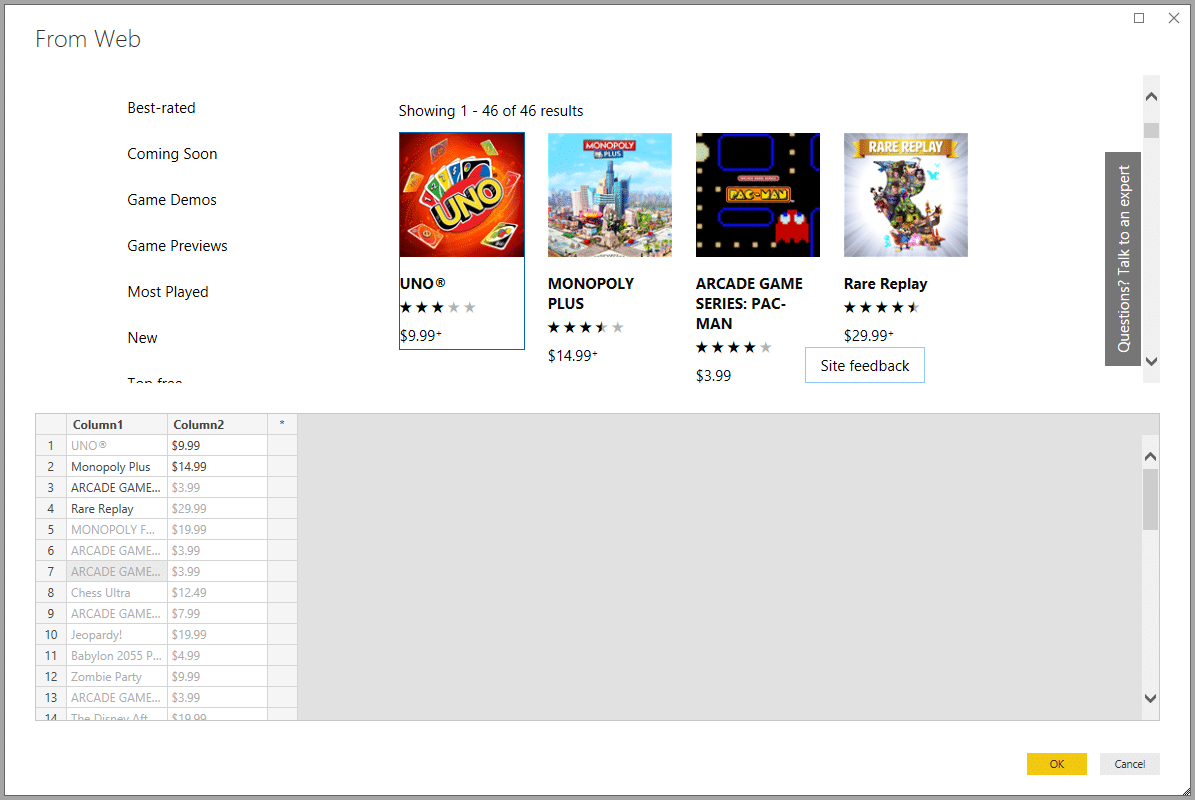
The rise of AI
The democratisation of artificial intelligence, particularly the Generative AI as ChatGPT, Bing Conversation or Bard, is changing the game. This type of AI makes it easy to retrieve information from the web or from PDF files extremely quickly. However, these AIs have the disadvantage of being generalists and not being able to export data easily in structured formats.
This requires the use of AI specialising in web scraping, such as Scrapestorm, kadoa.com, Nimbleway API or Browse.ai. Solutions from around twenty euros a month.
With AI of this kind, there's no need for programming. All you have to do is define the data to be extracted (prices, for example), one or more data sources (one or more websites) and specify how often the data is to be retrieved (every week, for example).
The AI takes care of everything else: it creates a program with the parameters you specify, extracts the data and sends it to you in the format you specify (Excel, CSV, JSON, etc.).
In addition to their ease of use, efficiency and speed, these web scraping AIs are capable of recognising and recovering any type of data (text, images, videos, links, other files). What's more, they are not blocked by dynamic pages or the usual security tools put in place by targeted sites, such as captchas or IP address blocking.
What are the limits of web scraping?
Web scraping is a major contributor to the proliferation of botsThese are software robots that crawl the web in search of data. They are even becoming an invasive species. A study by the American cyber security Imperva reveals that bots accounted for 47 % of Internet traffic in 2022 !
Technical limits
These bots include malicious programmes and web scraping bots that overload the servers they target. They multiply requests, reducing their performance and sometimes even crashing them. A nightmare for any system administrator!
Another unfortunate consequence, this time for marketing: this non-human traffic distorts the audience measurements of the targeted websites and therefore compromises the company's digital marketing strategy.
However, defences are being organised. To protect themselves from this invasion, more and more sites are resorting to different methods. technical solutions to ban bots These include captcha riddles to ask users to prove that they are human, banning IP addresses, automatically limiting the number of requests from a single IP, and so on.
Another solution is to complicate and regularly change the structure of the pages displayed:
- change the URL architecture (change the order of the parameters),
- modify the HTML code (change the names of classes and IDs, change the order of DOM elements)
- template rotation (if your site has a CMS, you can create several page templates and rotate them)
- offending the code (minification, obscuring variable and function names, loading content with JavaScript, encoding data)
- change the data structure (CSV, JSON, etc.)
- change the API structure if your site offers one
With all these changes, the code or parameters of the scraping solution will have to be updated to adapt, which reduces both their effectiveness and their value.
Legal limits
Like all data collection techniques, scraping is subject to French and European regulations, as well as to the general terms and conditions of use (GTCU) specific to each website.
The use of web scraping is therefore subject to three conditions:
1. Comply with the CGU of the data source site
In its T&Cs, LinkedIn formally prohibits web scraping:
"You agree not to develop, support or use any software, device, script, robot or other means or process (including, without limitation, spiders, browser plug-ins and add-ons, or any other technology) to web scrap the Services or otherwise copy profiles and other data from the Services.
Breaching these GTCs exposes the offender to penalties. Ignoring them is perilous, especially as more and more major platforms are introducing tools to detect web scraping.
2. Comply with GDPR
In addition to respecting the T&Cs, the web scraper must respect GDPRapplicable to all data processing. En the event of non-compliance, the penalties can amount to up to €20 million or, in the case of a company, up to 4% of worldwide annual turnover..
3. Respecting copyright
Databases are protected by copyright, and by a sui generis right (in its own right) protecting the producer (articles L. 112-3 and L. 341-1 of the French Intellectual Property Code). The maximum penalties for breaches are a fine of €300,000 and 3 years' imprisonment..
On 2 February 2021, the courts ruled in favour of the Leboncoin.fr website, whose property advertisements had been the subject of data extractions by a rival site.
In addition to the legal framework, there are a number of best practices to be observed:
- Practice web scraping outside peak hours of the site, when servers are more available;
- Limit the data recovered to what you really need ;
- Use the APIs and other resources (data sets, etc.) offered by the target site to avoid web scraping.
Web scraping means regularly updating your skills
Despite its technical and legal challenges, web scraping remains popular. It is a fantastic tool for automatically collecting data. ORSYS offers a range of face-to-face and distance learning courses to help you use one of the solutions we have presented.
Developers and data specialists (data analyst, data engineer, etc.) will be able to learn about big data and the use of Python libraries specialising in web scraping (scrapy, BeautifulSoup, Selenium, etc.).
We also offer training courses on how to clean and manipulate the data collected.
Web developers, CISO and system administrators may be interested in our training courses on website security to prevent web scraping and data theft.
CIOs, DP.O. and lawyers can follow our training courses to master the legal challenges of the RGPD.
Finally, non-computer scientists who want to make the most of web scraping in their business can turn to our Excel, Google Sheets or Power BI training courses.
Everyone will find his account.


