
Le web scraping Hiermee kun je automatisch gegevens van het web verzamelen voor informatie over concurrenten, het genereren van leads, het ontwikkelen van marketing- en verkoopstrategieën en nog veel meer. Maar je moet wel weten welke tools je moet gebruiken en wat het juridische kader is voor deze praktijk. Wij leggen alles uit.

Het web is een onschatbare bron van gegevens. Wat als je deze schat aan informatie gratis zou kunnen aanboren? Dat is waar web scraping over gaat, een efficiënte techniek om snel en automatisch webgegevens te verzamelen. U hoeft niet met de hand te kopiëren en te plakken. Veel tools voeren deze taak automatisch uit en verwerken duizenden gegevens in enkele seconden. Elke oplossing heeft zijn sterke en zwakke punten. Sommige vereisen codeervaardigheden, andere niet.
Waar is het voor? Voor wie is het?
De sectoren die het meest gebruikmaken van web scraping zijn sectoren die veel gegevens verwerken: e-commerce, financiën, sociale media, vastgoed, pers, wetenschap, enz. Binnen deze sectoren zijn de beroepen die er het meest gebruik van maken marketing, financiën, HR, SEO-specialisten en datawetenschappers.
Als de gegevens eenmaal zijn verzameld, kunnen bedrijven ze gebruiken om hun concurrentie-intelligentie te voeden of om hun eigen database te verrijken tegen lage kosten. Dit zijn de belangrijkste toepassingen:
- De prijzen en beschikbaarheid van producten en diensten controleren om de concurrentie te monitoren of markttrends te analyseren.
- Leads genereren door automatisch de achternamen, voornamen, functies en contactgegevens van professionals op te halen van LinkedIn, Twitter, Google Maps, Indeed, enz.
- Siteverwijzingen optimaliseren : de positie in de zoekresultaten en de positie ten opzichte van de concurrentie in de gaten houden.
- Analyseer online sentiment door klantbeoordelingen en opmerkingen op sociale netwerken te lezen.
- Links automatisch controleren. Dit is vooral nuttig in een affiliatiestrategie om ervoor te zorgen dat links niet verbroken of verouderd zijn.
- Monitor vacatures of verzamel informatie over potentiële kandidaten van vacaturesites of sociale netwerken
- Gegevenssets bouwen om een AI te trainen
- Zoeken naar inbreuken op het auteursrecht (plagiaat van afbeeldingen of teksten)
- Informatie verzamelen over een specifiek onderwerp. Maak bijvoorbeeld een automatisch persoverzicht van artikelen en innovaties op het gebied van batterijproductie.
Hoe werkt het?
Bij web scraping wordt een scraper gebruikt, een softwareprogramma dat informatie van websites haalt. De scraper interageert met de sites op dezelfde manier als een browser gemanipuleerd door een mens. Maar in plaats van de informatie weer te geven, wordt deze verzameld en opgeslagen voor latere analyse. Dit proces bestaat uit vier stappen:
- HTTP-verzoek De scraper stuurt een verzoek naar de doel-URL om de inhoud van een pagina te verkrijgen.
- Analyse van HTML-code De scraper identificeert de elementen met betrekking tot de gegevens die je zoekt.
- gegevensextractie Gegevens worden geëxtraheerd met behulp van selectors zoals XPath, CSS of reguliere expressies (regex).
- gegevensopslag : de informatie wordt opgeslagen in formaten die gebruikt kunnen worden voor analyse (Excel, CSV, JSON, enz.).
Hoe webscrapen te doen?
Voor ontwikkelaars
Ontwikkelaars zijn de meesters in scraping. Dankzij programmeertalen in combinatie met frameworks en bibliotheken die gespecialiseerd zijn in gegevensextractie, kunnen ze scrapers maken die perfect zijn aangepast aan de doelwebsite en de gegevens die moeten worden geëxtraheerd. Efficiëntie, schaalbaarheid en onderhoudbaarheid zijn hun sleutelwoorden.
Welke taal moet worden gebruikt? Als JavaScript (Node.js), Ruby, C, C++, R of PHP webscraping toestaan, Python heeft naam gemaakt in de afgelopen jaren dankzij twee tools, BeautifulSoup (een bibliotheek) en Scrapy (een framework).
Python en zijn twee add-ons zijn eenvoudig te leren, snel en draagbaar (Linux, Windows, macOS en BSD) en kunnen worden gebruikt voor elk web scraping-project.
Hier is een voorbeeld van een Python-programma dat de BeautifulSoup-bibliotheek gebruikt om alle prijzen van elektrische scheerapparaten op de website Amazon.co.uk op te halen.
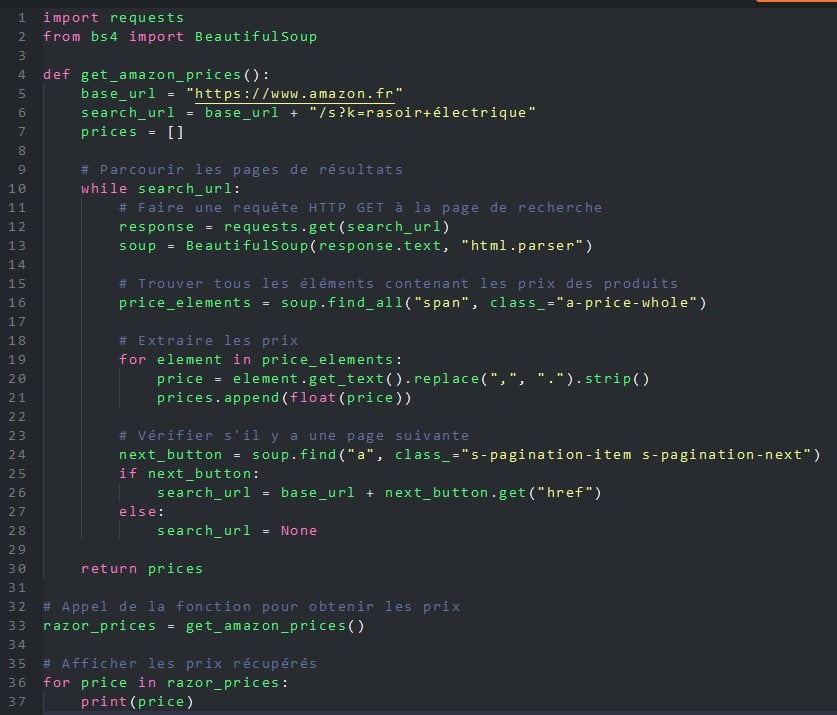
Voor niet-ontwikkelaars
Hoewel ontwikkelaars nog steeds het voordeel hebben om de meest effectieve tools voor web scraping te maken die het best geschikt zijn voor de behoeften van hun gebruikers, hebben ze niet langer een monopolie. Als gevolg daarvan, niet-IT-professionals, of het nu gaat om marketing, financiën of HR, maken steeds vaker gebruik van web scraping, maar dan zonder codering. Hiervoor gebruiken ze no-code tools die de afgelopen jaren zijn verschenen. Hier zijn er een paar.
Browser-extensies
Dit is de eenvoudigste manier om aan de slag te gaan met web scraping zonder codering: installeer een extensie in je webbrowser. Deze gratis en gebruiksvriendelijke plug-ins werken allemaal op dezelfde manier: eenmaal op de doelsite selecteer je de elementen die je wilt ophalen (tekst, afbeeldingen, URL, enz.), de frequentie (bijvoorbeeld eenmaal per uur, eenmaal per dag of eenmaal per week) en de extensie doet de rest. Enkele van de bekendste zijn Webschraper, Simplescraper, Scraper, Agenty of Instant Data Scraper.

Webscraping-platforms
Een andere oplossing waarvoor geen programmeerkennis nodig is, is het gebruik van een van de vele platforms die services voor web scraping aanbieden, zoals Octoparse, Bright Data, Parsehub of PhantomBuster. Met deze tools kun je - op basis van een abonnement - gegevens verzamelen van het web, maar ook van sociale platforms zoals Facebook, Instagram, Twitter, YouTube, etc. Je kunt informatie ophalen over hashtags, mentions, comments en likes. Deze gegevens kunnen worden gebruikt om trends en de prestaties van marketingcampagnes te analyseren.

Met behulp van een web scraping platform, in dit geval ParseHub, kunnen we de te verwerken gegevens selecteren (in dit geval de kledingcategorieën van een e-commerce site), extraheren en interpreteren. De onderstaande tabel analyseert de gemiddelde prijzen per productcategorie en fabrikant.
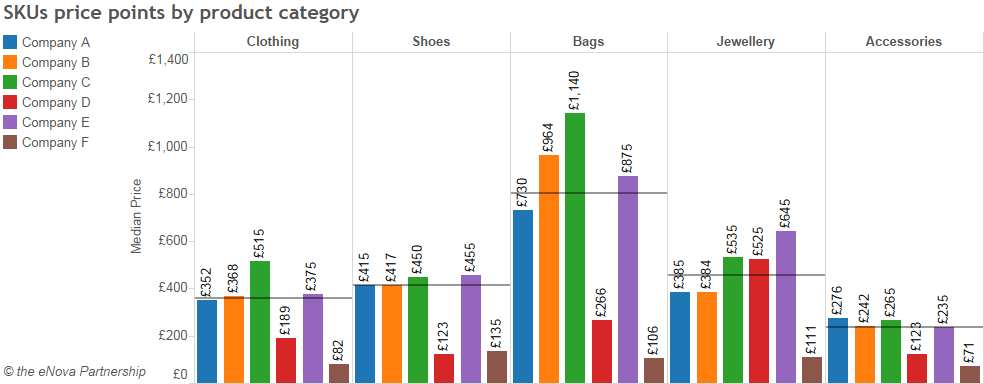
Het grote voordeel van deze platforms is dat ze no-code oplossingen bieden, die 24/7 in de cloud opereren. Je kunt dus scrapers plannen om gegevens te verkrijgen in een continue stroom of met flexibele tussenpozen. Een ander voordeel is dat je kunt kiezen uit tientallen kant-en-klare schrapers., waarmee u met slechts een paar klikken de populairste sites en platforms kunt targeten. Eindelijk, Deze cloudplatforms omzeilen veel van de beveiligingen die websites hebben ingesteld om zich te beschermen tegen web scraping. IP-rotatie, captcha's, proxy's, oneindig scrollen, enz.
Toepassingen gegevensanalyse
Google Spreadsheets, PowerBI, Excel... spreadsheets en datavisualisatietoepassingen kunnen worden gebruikt om met wisselend gemak gegevens van het web te halen.
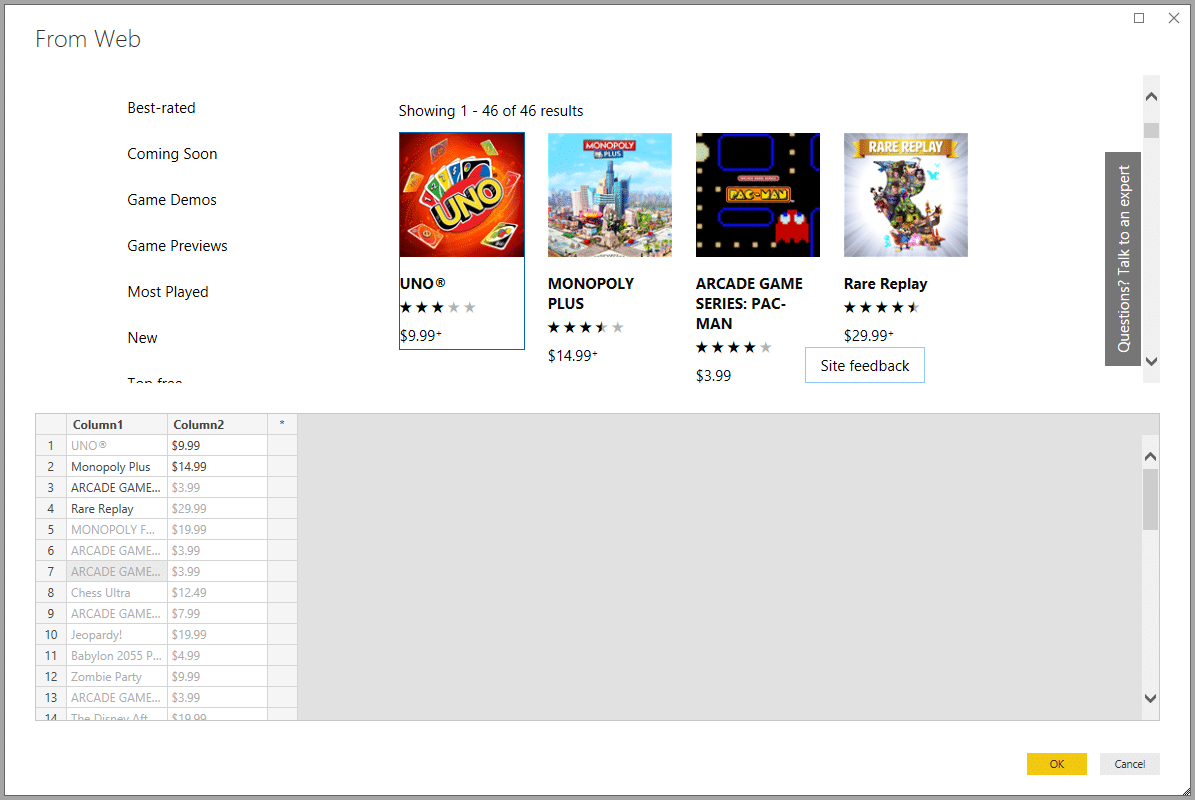
Soms moet je specifieke functies gebruiken. Dit is het geval met Google Sheets, dat gespecialiseerde functies heeft: IMPORTXML en IMPORTHTML. Je moet nog steeds de structuur van een HTML-pagina begrijpen om de formule correct te formaliseren en je doelen te bereiken.
Excel, Microsoft 365 en Power BI hebben gespecialiseerde modules voor gegevensextractie die eenvoudiger te implementeren zijn. Excel gebruikt bijvoorbeeld de Power Query-module (sinds Excel 2010) of een webquery-module uit het menu Data. Microsoft 365 profiteert op zijn beurt van de kracht van de automatiseringsmodule Power Automate. De Power BI-oplossing voor gegevensanalyse, nog steeds van dezelfde uitgever, bevat web scraping in het menu Get Data. Al deze wizards stellen automatisch voor om de tabellen op te halen die aanwezig zijn op de beoogde webpagina's, maar het is mogelijk om andere gegevensbronnen te definiëren.
De opkomst van AI
De democratisering van kunstmatige intelligentie, met name de Generatieve AI als ChatGPTBing Conversation of Bard, is het spel aan het veranderen. Met dit soort AI's is het eenvoudig om extreem snel informatie van het web of uit PDF-bestanden te halen. Deze AI's hebben echter het nadeel dat ze generalisten zijn en niet gemakkelijk gegevens kunnen exporteren in gestructureerde formaten.
Dit vereist het gebruik van AI's die gespecialiseerd zijn in web scraping, zoals Scrapestorm, kadoa.com, Nimbleway API of Browse.ai. Oplossingen vanaf ongeveer twintig euro per maand.
Met dit soort AI hoef je niet te programmeren. Het enige wat je hoeft te doen is de gegevens definiëren die moeten worden opgehaald (bijvoorbeeld prijzen), een of meer gegevensbronnen definiëren (een of meer websites) en aangeven hoe vaak de gegevens moeten worden opgehaald (bijvoorbeeld elke week).
De AI doet al het andere: het maakt een programma met de parameters die je opgeeft, haalt de gegevens eruit en stuurt ze naar je toe in het formaat dat je opgeeft (Excel, CSV, JSON, enz.).
Naast hun gebruiksgemak, efficiëntie en snelheid zijn deze web scraping AI's in staat om elk type gegevens te herkennen en terug te halen (tekst, afbeeldingen, video's, links, andere bestanden). Bovendien worden ze niet geblokkeerd door dynamische pagina's of de gebruikelijke beveiligingstools die zijn ingesteld door gerichte sites, zoals captcha's of IP-adresblokkering.
Wat zijn de grenzen van web scraping?
Web scraping levert een belangrijke bijdrage aan de verspreiding van botsDit zijn softwarerobots die het web afstruinen op zoek naar gegevens. Ze zijn zelfs een invasieve soort aan het worden. Een onderzoek door de Amerikaanse cyberveiligheid Imperva onthult dat bots goed voor 47 % van het internetverkeer in 2022 !
Technische limieten
Deze bots omvatten kwaadaardige programma's en web scraping bots die de servers waar ze zich op richten overbelasten. Ze vermenigvuldigen de aanvragen, waardoor ze minder goed presteren en soms zelfs crashen. Een nachtmerrie voor elke systeembeheerder!
Nog een ongelukkig gevolg, dit keer voor marketing: dit niet-menselijke verkeer verstoort de publieksmetingen van de beoogde websites en brengt daarom de digitale marketingstrategie van het bedrijf in gevaar.
Er worden echter verdedigingen georganiseerd. Om zich tegen deze invasie te beschermen, gebruiken steeds meer sites verschillende methoden. technische oplossingen om bots te verbieden Deze omvatten captcha-raadsels om gebruikers te vragen te bewijzen dat ze menselijk zijn, het verbannen van IP-adressen, het automatisch beperken van het aantal aanvragen vanaf één IP, enzovoort.
Een andere oplossing is om de structuur van de weergegeven pagina's ingewikkelder te maken en regelmatig te wijzigen:
- de URL-architectuur wijzigen (de volgorde van de parameters),
- de HTML-code wijzigen (de namen van klassen en ID's wijzigen, de volgorde van DOM-elementen wijzigen)
- Rotatie van sjablonen (als je site een CMS heeft, kun je verschillende paginasjablonen maken en deze laten roteren)
- de code beledigen (minificatie, variabele en functienamen verbergen, inhoud laden met JavaScript, gegevens coderen)
- de gegevensstructuur wijzigen (CSV, JSON, enz.)
- de API-structuur wijzigen als uw site die biedt
Als gevolg van al deze veranderingen moet de code of de parameters van de scraping-oplossing worden bijgewerkt om zich aan te passen, wat zowel hun effectiviteit als hun waarde vermindert.
Wettelijke grenzen
Zoals alle technieken om gegevens te verzamelen, is scraping onderworpen aan Franse en Europese regelgeving en aan de algemene gebruiksvoorwaarden die specifiek zijn voor elke website.
Het gebruik van web scraping is daarom onderworpen aan drie voorwaarden:
1. Voldoen aan de CGU van de gegevensbronlocatie
In de algemene voorwaarden verbiedt LinkedIn webscraping formeel:
"U stemt ermee in geen software, apparaten, scripts, robots of andere middelen of processen (met inbegrip van, maar niet beperkt tot, spiders, browserplug-ins en add-ons of enige andere technologie) te ontwikkelen, te ondersteunen of te gebruiken om de Services te scrapen of anderszins profielen en andere gegevens van de Services te kopiëren.
Het schenden van deze AVG stelt de overtreder bloot aan sancties. Ze negeren is gevaarlijk, vooral omdat steeds meer grote platforms tools introduceren om web scraping te detecteren.
2. Voldoe aan de AVG
Naast het respecteren van de Algemene Voorwaarden, moet de webschraper deze ook respecteren AVGvan toepassing op alle gegevensverwerking. EBij niet-naleving kunnen de boetes oplopen tot €20 miljoen of, in het geval van een bedrijf, tot 4% van de jaarlijkse wereldwijde omzet..
3. Auteursrecht respecteren
Databases worden beschermd door auteursrecht en door een recht sui generis (op zichzelf staand) dat de producent beschermt (artikelen L. 112-3 en L. 341-1 van de Franse wet op intellectueel eigendom). De maximale straffen voor overtredingen zijn een boete van €300.000 en 3 jaar gevangenisstraf..
Op 2 februari 2021 hebben de rechtbanken de website Leboncoin.fr in het gelijk gesteld, omdat een concurrerende site gegevens had geëxtraheerd uit advertenties voor onroerend goed.
Naast het wettelijke kader zijn er een aantal goede praktijken die in acht moeten worden genomen:
- Oefen met webscrapen buiten de spitsuren van de site, wanneer servers beter beschikbaar zijn;
- Beperk het aantal herstelde gegevens tot wat je echt nodig hebt ;
- Gebruik de API's en andere bronnen (gegevenssets, etc.) die worden aangeboden door de doelsite om web scraping te voorkomen.
Web scraping betekent het regelmatig bijwerken van je vaardigheden
Ondanks de technische en juridische uitdagingen blijft web scraping populair. Het is een fantastisch hulpmiddel om automatisch gegevens te verzamelen. ORSYS biedt een reeks cursussen voor face-to-face en afstandsonderwijs om u te helpen bij het gebruik van een van de oplossingen die we hebben gepresenteerd.
Ontwikkelaars en dataspecialisten (data-analist, data-engineer, enz.) kunnen leren over big data en het gebruik van Python-bibliotheken die gespecialiseerd zijn in web scraping (scrapy, BeautifulSoup, Selenium, enz.).
We bieden ook trainingen aan over het opschonen en manipuleren van de verzamelde gegevens.
Webontwikkelaars, CISO en systeembeheerders mogelijk geïnteresseerd zijn in onze trainingen over websitebeveiliging om web scraping en gegevensdiefstal.
CIO's, Dpostbus en advocaten kunnen onze trainingen volgen om de juridische uitdagingen van de RGPD.
Tenslotte, niet-computerwetenschappers die het meeste willen halen uit web scraping in hun bedrijf, kunnen terecht bij onze Excel, Google Sheets of Power BI trainingen.
Iedereen zal zijn account vinden.


