
Met de opschudding veroorzaakt door ChatGPT en zijn soortgenoten, brengt AI bedrijven in beroering. Dit is een kans om terug te gaan naar de basis: wat zijn de verschillen tussen een AI, de machinaal leren en de diep leren ? Denk je dat je alles weet? Nu is het tijd om je kennis op de proef te stellen!

Lees net een artikel over de bekwaamheid van ChatGPT of MidJourney om de termen kunstmatige intelligentie, deep learning en machine learning tegen te komen. Hun definities en betekenissen worden soms verward en vaak verkeerd begrepen. Toch verwijzen ze naar zeer verschillende concepten.
AI, machine learning, deep learning - waar hebben we het over?
Kunstmatige intelligentie
Kunstmatige intelligentie (AI) is het vermogen van een systeem om menselijke intelligentie te simuleren. De Amerikaanse pionier van AI, Marvin Minsky, had een preciezere definitie: AI is "een wetenschap waarvan het doel is om een machine taken te laten uitvoeren die mensen uitvoeren met behulp van hun intelligentie".
Dit omvat een breed scala aan systemen, van expertsystemen tot chatbots, l'machinaal lerennatuurlijke taalverwerking (NLP), de computervisiede autonome agentenDeze omvatten het gebruik van computermodellen, neurale netwerken en genetische algoritmen (een optimalisatiemethode geïnspireerd op het proces van natuurlijke selectie).
Machinaal leren
Le machine learning (ML), of automatisch leren, is een tak van kunstmatige intelligentie die computers in staat stelt om te leren zonder expliciet geprogrammeerd te zijn. Dit is de definitie die in 1959 werd gegeven door een van de pioniers, Arthur Samuel.
Machine learning werkt op basis van voorbeelden. Het gebruikt algoritmen om gegevens statistisch te analyseren en patronen te identificeren. Deze modellen worden vervolgens gebruikt om resultaten te voorspellen, een beter inzicht te krijgen in de processen die de gegevens genereren of om beslissingen te nemen.
Het gebruik ervan :
- Classificatie: classificeer bestanden op basis van hun inhoud, detecteer afwijkingen op een productielijn, detecteer spam, enz.
- Regressie: het voorspellen van een numerieke waarde, handig voor het voorspellen van het weer of een aandelenkoers.
- Groeperen: klanten groeperen op basis van persona en koopgewoonten
- Zoekmachines, aanbevelingsmachines...
- Gespreksagenten (chatbots)...
Diep leren
Le diep leren (DL), of diep lerenis een subset van machinaal leren. Het maakt gebruik van kunstmatige neurale netwerken (ANN's), algoritmen die geïnspireerd zijn op de manier waarop het menselijk brein werkt en die de manier nabootsen waarop neuronen signalen naar elkaar sturen. Deze neuronen zijn georganiseerd in onderling verbonden lagen met een bepaald niveau van diepte (het diepe van deep learning). Elk niveau van diepte helpt om de nauwkeurigheid van de resultaten te optimaliseren en te verfijnen.
Deep learning-algoritmen zijn bij uitstek geschikt om complexe problemen op te lossen. Ze vereisen een grote hoeveelheid gegevens en dus veel rekenkracht om deze te verwerken.
Het gebruik ervan beeldherkenning (gezondheid, industrie, enz.), automatische vertaling (Google Translate, DeepL, enz.), spraakherkenning (Siri, Alexa, enz.), financiële diensten (fraudedetectie), voorspellende analyserisicobeoordeling), zelfrijdende auto's, robotica (robots leren complexe taken uit te voeren), enz.
Laten we het allemaal samenvatten met een schets.
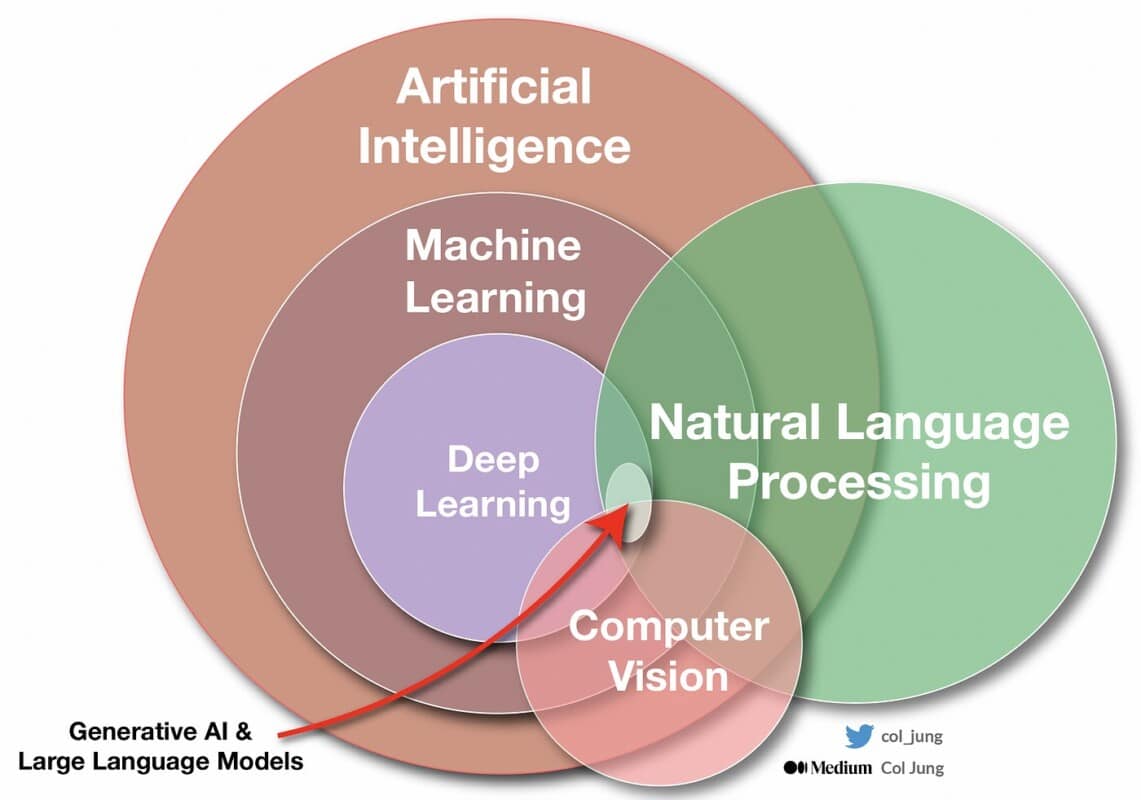
De verschillen tussen machine learning en deep learning
Soorten leren: onder toezicht, zonder toezicht, versterkt
Algoritmen voor machinaal leren en diep leren moeten leren van voorbeeldgegevens om hun gegevens aan te passen. parametersgenaamd trainingsdatasets (datasets trainen). Zonder training is kunstmatige intelligentie niets. De kwaliteit van de training bepaalt de kwaliteit van de resultaten. Er zijn verschillende soorten leren: supervised, semi-supervised, unsupervised en reinforcement learning.
Begeleid leren
Begeleid leren Hierbij helpen een of meer mensen de computer door hem trainingsgegevens te geven met het juiste antwoord op een vraag.
Is deze e-mail bijvoorbeeld spam of niet? Dankzij statistische analyse begrijpt het algoritme vervolgens met welke kenmerken het deze e-mails kan classificeren. Wanneer nieuwe e-mails aan het algoritme worden gepresenteerd, kan het ze identificeren en een waarschijnlijkheidsscore toekennen of ze spam zijn of niet. De mens wordt gebruikt om zijn fouten tijdens het leerproces te corrigeren, zodat het in de loop van de tijd kan verbeteren.
Leren zonder toezicht
Leren zonder toezicht is van toepassing als de antwoorden die we zoeken niet beschikbaar zijn in de dataset: de gegevens zijn niet gelabeld. Het algoritme werkt zonder menselijke tussenkomst. Het leert zichzelf hoe informatie te ontdekken uit een set gegevens. De resultaten kunnen minder nauwkeurig zijn dan bij leren onder toezicht.
Unsupervised learning wordt gebruikt om :
- gegevens clusteren op basis van overeenkomsten of verschillen. Bijvoorbeeld het groeperen van bankklanten op basis van hun profiel.
- associatiebewerkingen om relaties tussen variabelen in een gegevensverzameling te identificeren.
Andere soorten leren
Semi-supervised leren bestaat uit het leren van labels van een gedeeltelijk gelabelde dataset. Het voordeel hiervan is dat niet de hele trainingsdataset gelabeld hoeft te worden. Dit is vaak het geval bij het verwerken van een beelddatabase.
Versterking leren bestaat erin de computer te laten leren van zijn ervaringen door middel van een systeem van beloningen en straffen als de ondernomen actie een goede of slechte keuze was. Het doel van het algoritme is dan om een strategie te bepalen die de beloning maximaliseert. De belangrijkste toepassingen voor dit soort leren zijn spelletjes (schaken, Go, enz.) en robotica.
Soorten gegevens: gestructureerd en ongestructureerd
Een ander groot verschil tussen machine learning en deep learning is het type gegevens dat wordt ingevoerd in de dataset.
Le machinaal leren handelt met gestructureerde gegevensgegevens die zijn georganiseerd volgens een vooraf gedefinieerd model, dat gemakkelijk kan worden geïndexeerd zoals een tabel of een database, evenals ongestructureerde gegevensOngestructureerde gegevens zijn gegevens die geen bepaald model volgen. Ongestructureerde gegevens kunnen tekst, afbeeldingen, video, audio, enz. zijn.
Le diep leren wordt gebruikt voor het verwerken en analyseren van ongestructureerde gegevens.
Laten we het samenvatten in een tabel
Verschillen tussen Machine Learning en Deep Learning
| Kenmerken | Machinaal leren | Diep Leren |
|---|---|---|
| Type leren | Onder toezicht of zonder toezicht | Onder toezicht, semi-onder toezicht of door versterking |
| Menselijke interventie | Sterk tot gemiddeld | Laag |
| Type invoergegevens | Gestructureerd of ongestructureerd | Ongestructureerd |
| Type uitvoergegevens | Numerieke waarden | Numerieke waarden, tekst, afbeelding, stem, video... |
| Hoeveelheid vereiste gegevens | Laag tot gemiddeld (duizenden) | Hoog (miljoenen, zelfs miljarden) |
| Belang van gegevenskwaliteit | Zeer belangrijk | Belangrijk |
| Trainingstijd | Kort | Lang |
| Vereiste rekenkracht | Laag tot gemiddeld (CPU) | Sterk (GPU) |
Eindelijk
AI, machine learning en deep learning zijn drie verschillende elementen. AI is de discipline en, bij uitbreiding en metonymie, de producten of diensten gebaseerd op AI: Siri, ChatGPT, de AI van autonome auto's, deAI voor radiologie die steeds meer kankers detecteert...
Machine learning en deep learning zijn twee automatische leertechnieken die door AI worden gebruikt. Ze hebben echter verschillende toepassingen. Machine-learningalgoritmen verwerken kwantitatieve en gestructureerde gegevens, terwijl deep-learningalgoritmen ongestructureerde gegevens zoals geluid, tekst of afbeeldingen verwerken.
En wat zijn Generatieve AI zoals ChatGPT, Bard, DALL-E of MidJourney? Ze produceren tekst, afbeeldingen of code, of zijn zelfs multimodaal, en zijn gebaseerd op LLM (grote taalmodellen). Ze gebruiken deep learning en neurale netwerken om miljarden ongelabelde teksten te verwerken.
Als jij ook je eigen AI-modellen wilt maken, met AI wilt leren werken of gewoon meer wilt weten over deze revolutie, dan bieden we je de volgende opties aan zo'n zestig seminars en trainingen om je mee te nemen in deze spannende wereld!


