
Avec les bouleversements provoqués par ChatGPT et ses semblables, l’IA met l’entreprise dans tous ses états. L’occasion de revenir sur les fondamentaux : quelles sont les différences entre une IA, le machine learning et le deep learning ? Vous croyez tout savoir ? C’est le moment de confronter vos connaissances à la réalité !

Il suffit de lire un article sur les prouesses de ChatGPT ou de MidJourney pour rencontrer les termes Intelligence artificielle, deep learning, machine learning. Leur définition et leur sens sont parfois mélangés, souvent mal compris. Or, ils désignent des concepts bien distincts.
IA, machine learning, deep learning, de quoi parle-t-on ?
L’intelligence artificielle
L’intelligence artificielle (IA) est la capacité d’un système à simuler l’intelligence humaine. Le pionnier américain de l’IA, Marvin Minsky, avait une définition plus précise : l’IA est « une science dont le but est de faire réaliser par une machine des tâches que l’homme accomplit en utilisant son intelligence. »
Cela recouvre donc des systèmes très divers : les systèmes experts, les chatbots, l’apprentissage automatique (machine learning), les traitements du langage naturel (NLP), la vision par ordinateur, les agents autonomes, les réseaux de neurones, les algorithmes génétiques (méthode d’optimisation inspirée par le processus de sélection naturelle), etc.
Le machine learning
Le machine learning (ML), ou apprentissage automatique, est une branche de l’intelligence artificielle qui permet aux ordinateurs d’apprendre sans avoir été explicitement programmés. Cette définition est celle donnée en 1959 par un de ses pionniers, Arthur Samuel.
Le machine learning travaille à partir d’exemples. Il utilise des algorithmes pour analyser statistiquement des données et identifier des modèles. Ces modèles sont ensuite utilisés pour prédire des résultats, avoir une meilleure compréhension des processus qui génèrent ces données ou pour prendre des décisions.
Ses utilisations :
- La classification : classer des fichiers en fonction de leur contenu, détecter des anomalies sur une chaine de production, détecter des spams…
- La régression : prédire une valeur numérique, utile pour connaître l’évolution de la météo ou du cours d’une action
- Le regroupement : regrouper des clients par persona et habitudes d’achat
- Moteurs de recherche, moteurs de recommandation…
- Agents conversationnels (chatbots)…
Le deep learning
Le deep learning (DL), ou apprentissage profond, est un sous-ensemble du machine learning. Il utilise des réseaux de neurones artificiels (AAN), des algorithmes qui s’inspirent du fonctionnement du cerveau humain, imitant la manière dont les neurones s’envoient des signaux. Ces neurones sont organisés en couches interconnectées avec un certain niveau de profondeur (le deep de deep learning). Chaque niveau de profondeur contribue à optimiser et à affiner la précision des résultats.
Les algorithmes de deep learning sont très adaptés à la résolution de problèmes complexes. Ils nécessitent un grand volume de données et par conséquent une très grande puissance de calcul pour les traiter.
Ses utilisations : reconnaissance d’image (santé, industrie…), traduction automatique (Google Traduction, DeepL…), reconnaissance vocale (Siri, Alexa…), services financiers (détection des fraudes, analyses prédictives, évaluation des risques), voitures à conduite autonome, robotique (apprendre aux robots à effectuer des tâches complexes), etc.
Résumons le tout par un croquis.
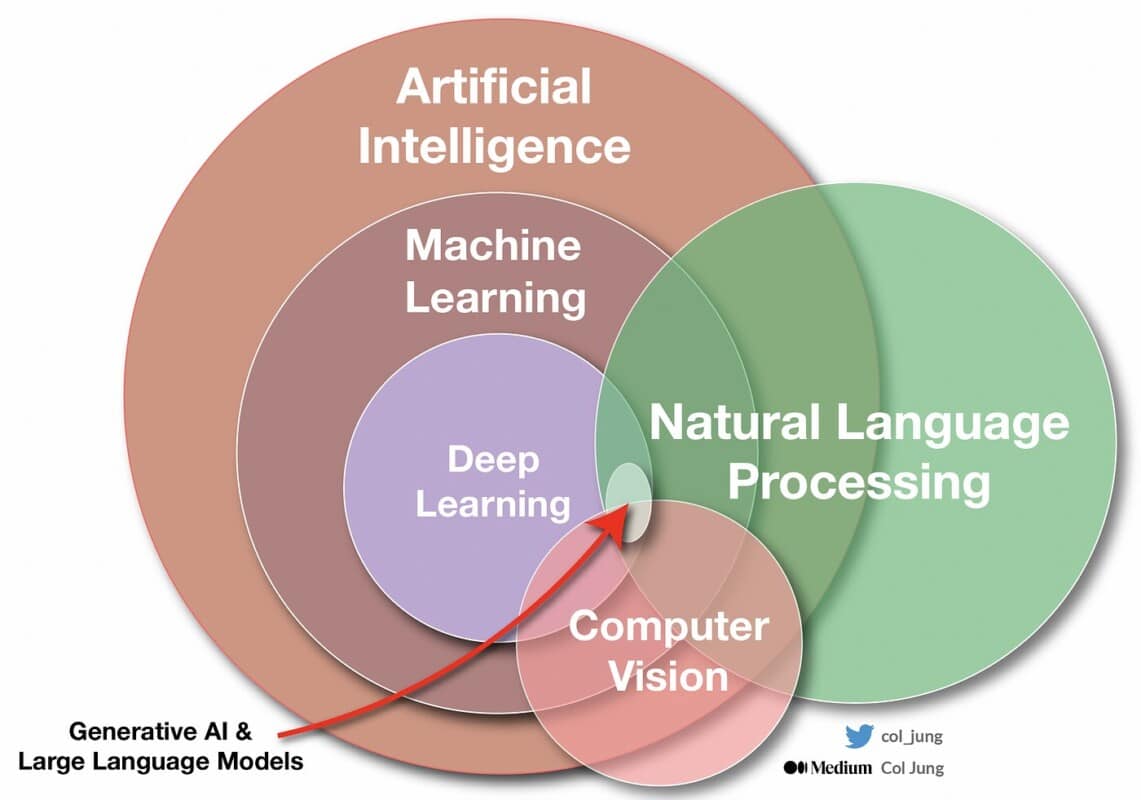
Les différences entre machine learning et deep learning
Les types d’apprentissages : supervisé, non supervisé, renforcé
Les algorithmes de machine learning et de deep learning ont besoin d’apprendre à partir de données d’exemples pour ajuster leurs paramètres, appelées jeux de données d’entraînement (train datasets). Sans entraînement, l’intelligence artificielle n’est rien. La qualité de l’apprentissage conditionne la qualité des résultats. Il existe plusieurs types d’apprentissages : supervisé, semi-supervisé, non supervisé ou par renforcement.
L’apprentissage supervisé
L’apprentissage supervisé consiste à ce qu’un ou des humains aident l’ordinateur en lui fournissant de données d’entraînement étiquetées avec la bonne réponse à une question.
Par exemple, est-ce que ce mail est un spam ou non ? Grâce à l’analyse statistique, l’algorithme comprend alors quelles sont les caractéristiques (features) qui lui permettent de classer ces e-mails. Ainsi, au fur et à mesure qu’on lui présentera de nouveaux e-mails, il pourra les identifier et leur attribuer un score de probabilité qu’ils soient ou non du spam. L’humain servira à corriger ses erreurs au cours du processus d’apprentissage afin qu’il s’améliore au fil du temps.
L’apprentissage non supervisé
L’apprentissage non supervisé s’applique quand les réponses que l’on cherche à obtenir ne sont pas disponibles dans le jeu de données : les données ne sont pas étiquetées. L’algorithme fonctionne sans intervention humaine. Il apprend lui-même à découvrir des informations à partir d’un ensemble de données. Ses résultats peuvent être moins précis que l’apprentissage supervisé.
L’apprentissage non supervisé est utilisé pour :
- les opérations de regroupement (clustering) de données en fonction de leurs similitudes ou de leurs différences. Par exemple, regrouper des clients d’une banque selon leur profil.
- les opérations d’association pour identifier les relations entre les variables d’un ensemble de données.
Les autres types d’apprentissages
L’apprentissage semi-supervisé consiste à apprendre des étiquettes à partir d’un jeu de données partiellement étiqueté. L’avantage est que cela évite d’avoir à étiqueter l’intégralité du jeu de données d’apprentissage. C’est souvent le cas pour le traitement d’une banque d’images.
L’apprentissage par renforcement consiste à laisser l’ordinateur apprendre de ses expériences grâce à un système de récompense et de pénalité si l’action entreprise était un bon ou mauvais choix. Le but de l’algorithme sera alors de définir une stratégie permettant de maximiser sa récompense. Les applications principales de ce type d’apprentissage sont les jeux (échecs, go…) et la robotique.
Les types de données : structurées et non structurées
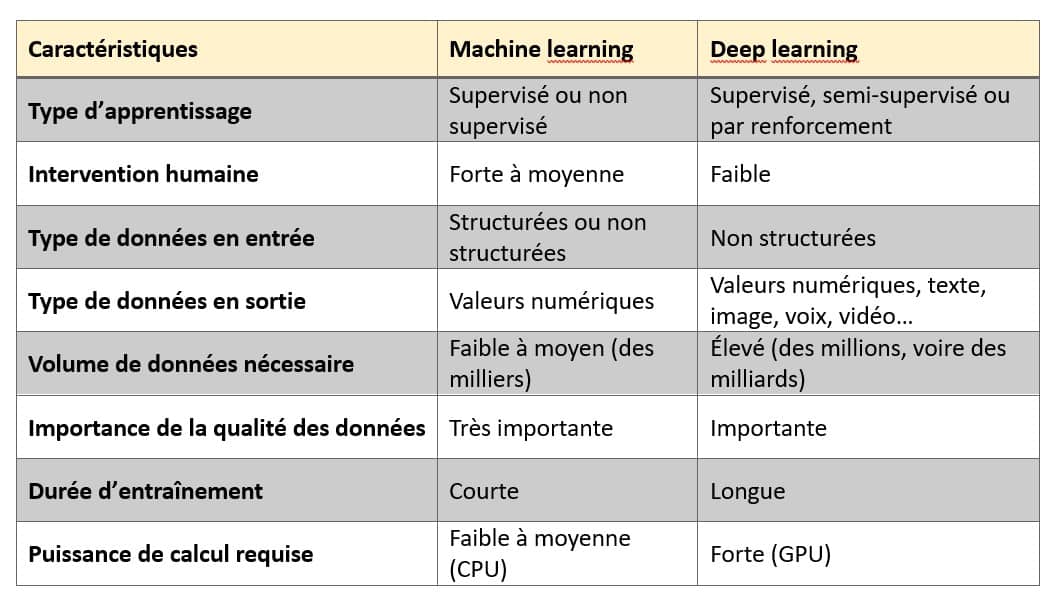
Autre grande différence entre le machine learning et le deep learning : le type de données en entrée du jeu de données.
Le machine learning traite des données structurées, des données organisées selon un modèle prédéfini, facilement indexables comme un tableau ou une base de données, aussi bien que des données non structurées, des données qui ne suivent pas de modèle particulier. Les données non structurées peuvent être du texte, des images, des vidéos, de l’audio, etc.
Le deep learning sert à traiter et à analyser des données non structurées.
Résumons par un tableau
Au final
IA, machine learning et deep learning sont trois éléments distincts. L’IA, c’est la discipline et par extension et métonymie, les produits ou les services basés sur l’IA : Siri, ChatGPT, l’IA des voitures autonomes, l’IA de radiologie qui détecte de plus en plus de cancers…
Le machine learning et le deep learning sont deux techniques d’apprentissage automatiques utilisées par l’IA. Leurs usages sont toutefois différents. Les algorithmes de machine learning vont traiter les données quantitatives et structurées alors que ceux de deep learning vont s’attacher au traitement des données non structurées, comme le son, le texte ou les images.
Et que sont les IA génératives comme ChatGPT, Bard, DALL-E ou MidJourney ? Elles produisent du texte, des images ou du code, voire sont multimodales, et sont basées sur des LLM (large language models). Elles font donc appel à du deep learning et à des réseaux de neurones pour traiter des milliards de textes non étiquetés.
Si vous souhaitez, vous aussi, créer vos propres modèles d’IA, apprendre à travailler avec des IA ou simplement en savoir plus sur cette révolution, nous vous proposons une soixantaine de séminaires et formations pour vous embarquer dans ce monde passionnant !


