
El raspado web le permite recopilar automáticamente datos de la web con fines de inteligencia competitiva, generación de clientes potenciales, desarrollo de estrategias de marketing y ventas y mucho más. Pero hay que saber qué herramientas utilizar y el marco legal que regula esta práctica. Nosotros se lo explicamos todo.

La red es una fuente de datos inestimable. ¿Y si pudieras aprovechar esta riqueza de información de forma gratuita? En eso consiste el web scraping, una técnica eficaz para recopilar datos web de forma rápida y automática. No es necesario copiar y pegar a mano. Muchas herramientas realizan automáticamente esta tarea y procesan miles de datos en cuestión de segundos. Cada solución tiene sus puntos fuertes y débiles. Algunas requieren conocimientos de codificación, otras no.
¿Para qué sirve? ¿A quién va dirigido?
Los sectores que más recurren al web scraping son los que manejan muchos datos: comercio electrónico, finanzas, redes sociales, inmobiliario, prensa, ciencia, etc. Dentro de estos sectores, las profesiones que más lo utilizan son las de marketing, finanzas, RRHH, especialistas en SEO y científicos de datos.
Una vez recogidos los datos, las empresas pueden utilizarlos para alimentar su inteligencia competitiva o enriquecer su propia base de datos a bajo coste. He aquí los principales usos:
- Controlar los precios y la disponibilidad de productos y servicios vigilar a la competencia o analizar las tendencias del mercado.
- Generar clientes potenciales recuperando automáticamente los apellidos, nombres, funciones y datos de contacto de profesionales de LinkedIn, Twitter, Google Maps, Indeed, etc.
- Optimización de la referenciación de sitios web : controlar su clasificación en los resultados de búsqueda y su posición en relación con sus competidores.
- Analizar el sentimiento en línea leyendo las opiniones y comentarios de los clientes en las redes sociales.
- Comprobación automática de enlaces. Esto es especialmente útil en una estrategia de afiliación para garantizar que los enlaces no estén rotos u obsoletos.
- Supervisar las ofertas de empleo o recopilar información sobre candidatos potenciales de bolsas de trabajo o redes sociales
- Creación de conjuntos de datos para entrenar una IA
- Búsqueda de infracciones de derechos de autor (plagio de imágenes o textos)
- Recopilar información sobre un tema concreto. Por ejemplo, producir una revista de prensa automática de artículos e innovaciones en la producción de pilas.
¿Cómo funciona?
El web scraping utiliza un scraper, una herramienta informática que extrae información de los sitios web. El scraper interactúa con los sitios de la misma manera que un navegador manipulado por un humano. Pero en lugar de mostrar la información, la recopila y la guarda para su posterior análisis. Este proceso consta de cuatro etapas:
- Solicitud HTTP El scraper envía una petición a la URL de destino para obtener el contenido de una página.
- análisis de código HTML El rascador identifica los elementos relacionados con los datos que busca.
- extracción de datos Los datos se extraen utilizando selectores como XPath, CSS o expresiones regulares (regex).
- almacenamiento de datos : la información se registra en formatos que pueden utilizarse para el análisis (Excel, CSV, JSON, etc.).
¿Cómo hacer web scraping?
Para desarrolladores
Los desarrolladores son los maestros del scraping. Utilizando lenguajes de programación combinados con marcos de trabajo y bibliotecas especializadas en la extracción de datos, pueden crear scrapers perfectamente adaptados al sitio web de destino y a los datos que deben extraerse. Eficacia, escalabilidad y facilidad de mantenimiento son sus consignas.
¿Qué lengua debe utilizarse? Si JavaScript (Node.js), Ruby, C, C++, R o PHP permiten el web scraping, Python se ha hecho un nombre en los últimos años gracias a dos herramientas, BeautifulSoup (una biblioteca) y Scrapy (un framework).
Fácil de aprender, rápido y portátil (Linux, Windows, macOS y BSD), Python y sus dos complementos pueden utilizarse para cualquier proyecto de web scraping.
He aquí un ejemplo de programa Python que utiliza la biblioteca BeautifulSoup para recuperar todos los precios de las máquinas de afeitar eléctricas en el sitio web Amazon.co.uk.
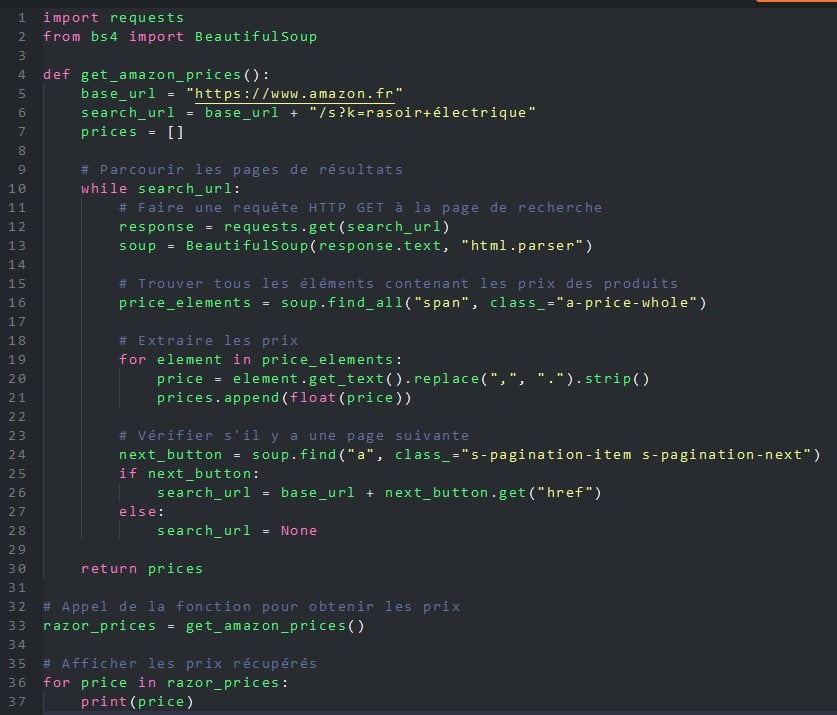
Para no desarrolladores
Aunque los desarrolladores siguen teniendo la ventaja de crear las herramientas de web scraping más eficaces y que mejor se adaptan a las necesidades de sus usuarios, ya no tienen el monopolio. En consecuencia, Los profesionales no informáticos, ya sean de marketing, finanzas o recursos humanos, utilizan cada vez más el web scraping, pero sin codificar. Para ello, utilizan herramientas sin código que han surgido en los últimos años. He aquí algunas de ellas.
Extensiones del navegador
Esta es la forma más fácil de empezar a hacer web scraping sin codificar: instalar una extensión en tu navegador. Gratuitos y fáciles de usar, todos estos plug-ins funcionan de la misma manera: una vez en el sitio de destino, usted selecciona los elementos que desea recuperar (texto, imágenes, URL, etc.), la frecuencia (una vez a la hora, una vez al día o una vez a la semana, por ejemplo) y la extensión se encarga del resto. Algunas de las más conocidas son Web Scraper, Simplescraper, Scraper, Agenty o Instant Data Scraper.

Plataformas de raspado web
Otra solución que no requiere conocimientos de programación es utilizar una de las muchas plataformas que ofrecen servicios de web scraping, como por ejemplo Octoparse, Bright Data, Parsehub o PhantomBuster. Estas herramientas le permiten -mediante suscripción- recopilar datos de la web, así como de plataformas sociales como Facebook, Instagram, Twitter, YouTube, etc. Puede recuperar información sobre hashtags, menciones, comentarios y me gusta. Estos datos pueden utilizarse para analizar tendencias y el rendimiento de las campañas de marketing.

Utilizando una plataforma de web scraping, en este caso ParseHub, podemos seleccionar los datos a procesar (en este caso, las categorías de ropa de un sitio de comercio electrónico), extraerlos e interpretarlos. La siguiente tabla analiza los precios medios por categoría de producto y fabricante.
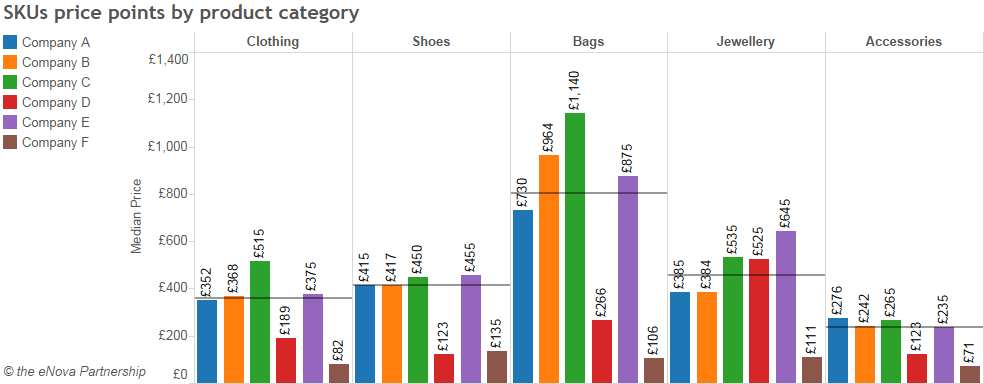
La gran ventaja de estas plataformas es ofrecer soluciones sin código, operando en la nube 24 horas al día, 7 días a la semana.. Por tanto, puede programar los rascadores para obtener datos de forma continua o a intervalos flexibles. Otra ventaja es que puede elegir entre docenas de rascadores listos para usar., capaz de apuntar a los sitios y plataformas más populares con solo unos pocos clics. Finalmente, estas plataformas en la nube eluden muchas de las protecciones establecidas por los sitios web para protegerse del web scraping Rotación de IP, captchas, proxies, desplazamiento infinito, etc.
Las aplicaciones análisis de datos
hojas de Google, Energía BI, sobresalir... hojas de cálculo y aplicaciones de visualización de datos pueden utilizarse para extraer datos de la web con mayor o menor facilidad.
A veces es necesario utilizar funciones específicas. Es el caso de Google Sheets, que dispone de funciones especializadas: IMPORTXML e IMPORTHTML. Aun así, necesitas entender la estructura de una página HTML para formalizar correctamente la fórmula y lograr tus objetivos.
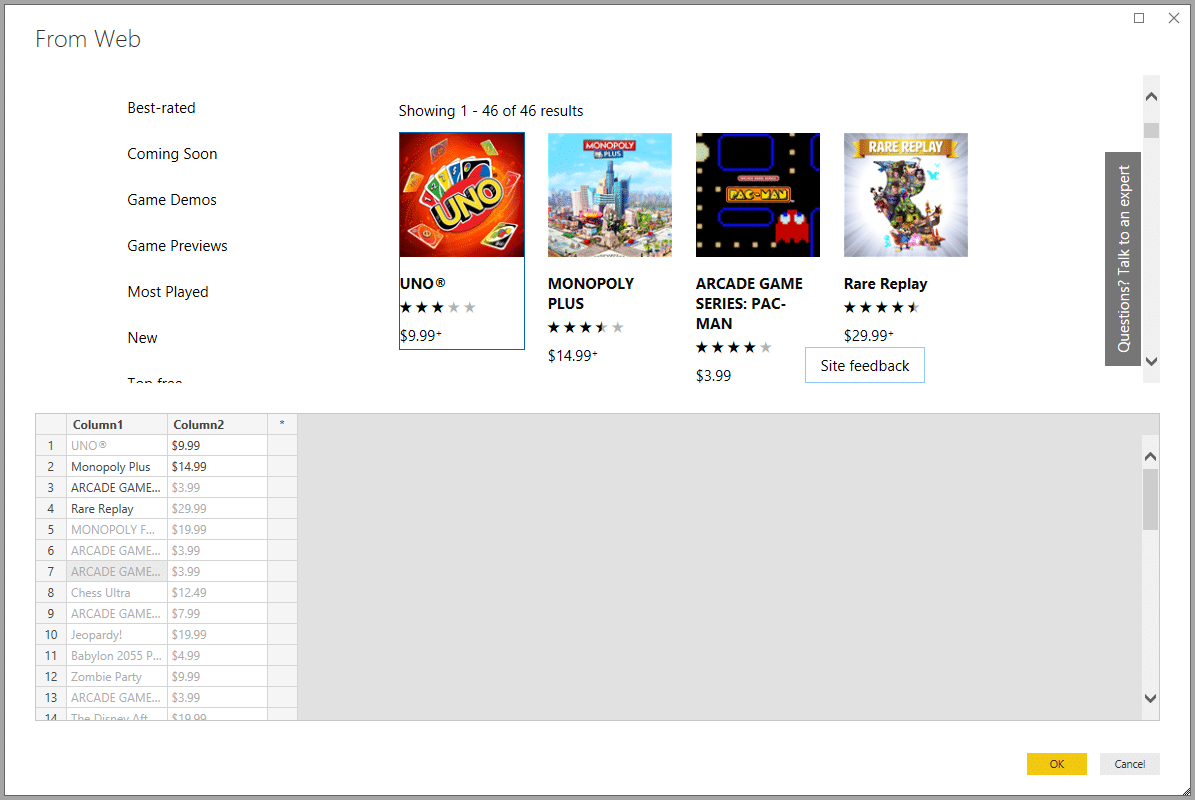
Excel, Microsoft 365 y Power BI disponen de módulos especializados de extracción de datos más fáciles de implementar. Por ejemplo, Excel utiliza el módulo Power Query (desde Excel 2010) o un módulo de consulta web desde el menú Datos. Por su parte, Microsoft 365 se beneficia de la potencia de su módulo de automatización Power Automate. Siempre del mismo editor, la solución de análisis de datos Power BI incluye el web scraping en su menú Obtener datos. Todos estos asistentes proponen automáticamente recuperar las tablas presentes en las páginas web objetivo, pero es posible definir otras fuentes de datos.
El auge de la IA
La democratización de la inteligencia artificial, en particular la IA Generativa como ChatGPTBing Conversation o Bard, está cambiando las reglas del juego. Este tipo de IA facilita la recuperación de información de la web o de archivos PDF con extrema rapidez. Sin embargo, estas IA tienen el inconveniente de ser generalistas y no poder exportar fácilmente datos en formatos estructurados.
Para ello es necesario utilizar IA especializadas en el raspado web, como Scrapestorm, kadoa.com, Nimbleway API o Browse.ai. Soluciones desde unos veinte euros al mes.
Con este tipo de IA no hace falta programar. Basta con definir los datos que hay que extraer (precios, por ejemplo), una o varias fuentes de datos (uno o varios sitios web) y especificar la frecuencia con la que hay que recuperar los datos (cada semana, por ejemplo).
La IA se encarga de todo lo demás: crea un programa con los parámetros que especifiques, extrae los datos y te los envía en el formato que especifiques (Excel, CSV, JSON, etc.).
Además de su facilidad de uso, eficacia y rapidez, estas IAs de web scraping son capaces de reconocer y recuperar cualquier tipo de datos (texto, imágenes, vídeos, enlaces, otros archivos). Además, no son bloqueadas por las páginas dinámicas ni por las herramientas de seguridad habituales de los sitios objetivo, como los captchas o el bloqueo de direcciones IP.
¿Cuáles son los límites del web scraping?
El raspado de páginas web contribuye en gran medida a la proliferación de botsSe trata de robots informáticos que rastrean la web en busca de datos. Incluso se están convirtiendo en una especie invasora. Un estudio de la American ciberseguridad Imperva revela que los bots representarán 47 % del tráfico de Internet en 2022 !
Límites técnicos
Estos bots incluyen programas maliciosos y bots de web scraping que sobrecargan los servidores a los que se dirigen. Multiplican las peticiones, reduciendo su rendimiento y a veces incluso colapsándolos. Una pesadilla para cualquier administrador de sistemas.
Otra consecuencia desafortunada, esta vez para el marketing: este tráfico no humano distorsiona las mediciones de audiencia de los sitios web objetivo y, por tanto, compromete la estrategia de marketing digital de la empresa.
Sin embargo, se están organizando defensas. Para protegerse de esta invasión, cada vez más sitios recurren a distintos métodos. Soluciones técnicas para prohibir bots. Entre ellas están los acertijos captcha para pedir a los usuarios que demuestren que son humanos, la prohibición de direcciones IP, la limitación automática del número de peticiones desde una misma IP, etc.
Otra solución es complicar y cambiar regularmente la estructura de las páginas mostradas:
- cambiar la arquitectura de la URL (cambiar el orden de los caracteres parámetros),
- modificar el código HTML (cambiar los nombres de las clases y los ID, cambiar el orden de los elementos DOM)
- rotación de plantillas (si su sitio tiene un CMS, puede crear varias plantillas de página y rotarlas)
- ofender el código (minificación, ocultación de nombres de variables y funciones, carga de contenidos con JavaScript, codificación de datos)
- cambiar la estructura de los datos (CSV, JSON, etc.)
- cambiar la estructura de la API si su sitio ofrece una
Con todos estos cambios, el código o los parámetros de la solución de scraping tendrán que actualizarse para adaptarse, lo que reduce tanto su eficacia como su valor.
Límites legales
Como todas las técnicas de recogida de datos, el scraping está sujeto a la normativa francesa y europea, así como a las condiciones generales de uso (CGU) específicas de cada sitio web.
Por tanto, el uso del web scraping está sujeto a tres condiciones:
1. Cumplir con la CGU del sitio fuente de datos
En sus términos y condiciones, LinkedIn prohíbe formalmente el web scraping:
"Usted se compromete a no desarrollar, apoyar o utilizar ningún software, dispositivo, script, robot u otros medios o procesos (incluyendo, sin limitación, arañas, plug-ins del navegador y complementos, o cualquier otra tecnología) para hacer web scrap de los Servicios o copiar de otro modo perfiles y otros datos de los Servicios.
El incumplimiento de estas CGC expone al infractor a sanciones. Ignorarlas es peligroso, sobre todo porque cada vez más plataformas importantes están introduciendo herramientas para detectar el web scraping.
2. Cumplir con el RGPD
Además de respetar los T&C, el web scraper debe respetar RGPDaplicable a todo tratamiento de datos. En caso de incumplimiento, las sanciones pueden ascender hasta 20 millones de euros o, en el caso de una empresa, hasta 4% de la facturación anual mundial..
3. Respetar los derechos de autor
Las bases de datos están protegidas por derechos de autor y por un derecho sui generis (de pleno derecho) que protege al productor (artículos L. 112-3 y L. 341-1 del Código de la Propiedad Intelectual francés). Las penas máximas por infracción son una multa de 300.000 euros y 3 años de cárcel..
El 2 de febrero de 2021, los tribunales fallaron a favor del sitio web Leboncoin.fr, cuyos anuncios inmobiliarios habían sido objeto de extracciones de datos por parte de un sitio rival.
Además del marco jurídico, hay una serie de buenas prácticas que deben observarse:
- Practique el web scraping fuera de las horas pico del sitio, cuando los servidores están más disponibles;
- Limite los datos recuperados a lo que realmente necesita ;
- Utilizar las API y otros recursos (conjuntos de datos, etc.) ofrecidos por el sitio de destino. para evitar el web scraping.
El Web scraping implica actualizar regularmente tus conocimientos
A pesar de sus dificultades técnicas y jurídicas, el web scraping sigue siendo popular. Es una herramienta fantástica para recopilar datos de forma automática. ORSYS ofrece una serie de cursos presenciales y a distancia para ayudarle a utilizar alguna de las soluciones que hemos presentado.
Desarrolladores y especialistas en datos (analista de datos, ingeniero de datos, etc.) podrá aprender sobre big data y el uso de librerías Python especializadas en web scraping (scrapy, BeautifulSoup, Selenium, etc.).
También ofrecemos cursos de formación sobre cómo limpiar y manipular los datos recogidos.
Desarrolladores web, CISO y administradores de sistemas puede que le interesen nuestros cursos de formación sobre seguridad de sitios web para evitar el web scraping y el robo de datos.
CIO, DCORREOS. y abogados pueden seguir nuestros cursos de formación para dominar las RGPD.
Finalmente, los no informáticos que quieran sacar el máximo partido del web scraping en su empresa pueden recurrir a nuestros cursos de formación sobre Excel, Google Sheets o Power BI.
Cada uno encontrará su cuenta.


